ChatGPTは凄い
おじさんは仕事で、フォルダの中に無数にある同じフォーマットのエクセルファイルの特定列にある値にどんな種類があるを知る必要がありました。
パッとイメージすると、全部のエクセルファイルを開いて、特定列を1つずつコピーし、新たなエクセルファイルに貼り付けるのを繰り返し、最後に重複データを削除すればできそうです。
今回おじさんはこれを自動化してみました。プログラムはChatGPTにpythonで作って頂きました。
下のサイトでユーザ登録してログインします。
以下のような質問をしてみました。おじさんは列と行を間違えて聞いてます。
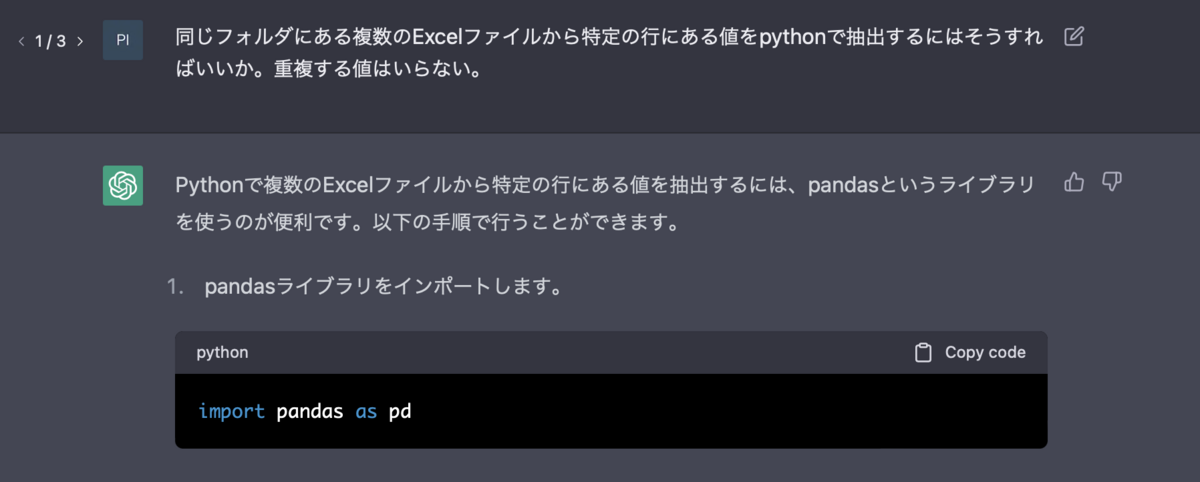
その結果、こんなプログラムを教えてくれました。
import os
import pandas as pd
# フォルダ内の全てのExcelファイルのパスを取得する
folder_path = "フォルダのパス"
files = os.listdir(folder_path)
excel_files = [f for f in files if f.endswith(".xlsx")]
# 抽出したい列の番号を指定する
col_num = 2
# 抽出した値を格納するリストを初期化する
values = []
for file in excel_files:
# Excelファイルを読み込む
df = pd.read_excel(os.path.join(folder_path, file), sheet_name="シート名")
# 特定の列の値を抽出する
value = df.iloc[0, col_num]
# 重複する値はいらないため、リストに追加する前に重複をチェックする
if value not in values:
values.append(value)
フォルダパス、シート名、列番号を記載し、このまま実行可能でした。コメントまでつけてくれます。1月前より進化している印象を受けました。何をしたいか質問するだけでちゃんと動作するプログラムを提示してくれます。無料で使えますので、これは使わない手はないですね。
その後、改めて実行結果を見ると、誤りに気がつきました。これでは1行目しか抽出されません。
# 特定の列の値を抽出する
value = df.iloc[0, col_num]
こういう時は回答の再生成です。Regenerate responseをクリックします。
import os
import pandas as pd
# フォルダ内の全てのExcelファイルのパスを取得する
folder_path = "フォルダのパス"
files = os.listdir(folder_path)
excel_files = [f for f in files if f.endswith(".xlsx")]
# 重複を除いた値を格納するセット
values_set = set()
# Excelファイルを読み込み、特定の列の値をセットに追加する
for file in excel_files:
df = pd.read_excel(os.path.join(folder_path, file))
values = df['列名'].tolist()
values_set.update(set(values))
print(values_set)
よりシンプルになりました。こういうトライ&エラーで少しずつpythonを理解していくのが、挫折のないプログラミングのやり方です。
考え方を少し変えると、プログラムに挫折というものはなくなります。